抖音喜欢列表怎么翻到最早的(抖音喜欢列表怎么倒序查看)
更新时间:2023-08-13 17:21:00来源:金符游戏浏览量:
工欲善其事,必先利其器。
爬取网页数据,一般都是采用页面Xpath和请求接口取得数据。两种方式都有弊端,Xpath 需要不停的定位和寻找数据的位置,接口不仅需要查找接口,而且需要加密解密。
目标网站
demo用获取抖音的推荐接口,这个接口是加密的。接口地址是:/aweme/v1/web/aweme/post/(开发者工具中的网络标签可以找到接口)
之前分享过一次用代码片段(code snippet)的方式,有些人可能尝试过。对js的熟悉程度很高,门槛不低。但是不妨碍学习,因为你发现只需要变更url地址就可以获取到数据。
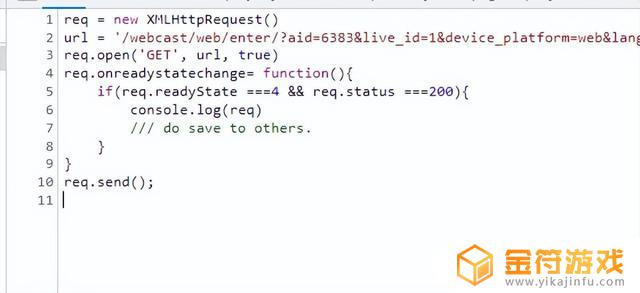
代码片段
我们用代码片段的目的是要拿到加密后的请求地址。今天我们分享python的方式,用更简单的方式来处理数据。

copy代码片段到编辑器
依然是RPC的方式(在本地执行远程js方法,解决扣js补环境的问题),browser 是 selenium,定义一个类,代码稍微的规范一下。signatureurlget 方法里面是上面图的内容。init只是初始化了一个webdriver.ChromeOptions()。
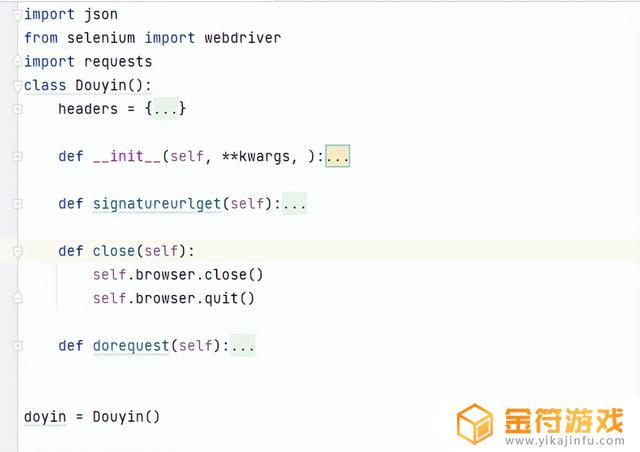
规范一下代码
运行一下,获取到加密的地址。请求加密的地址,获取到结果
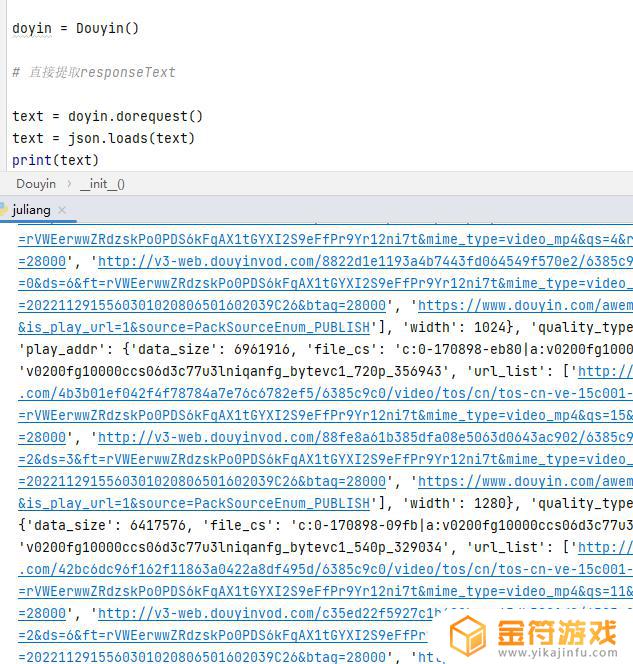
这样就能直接使用返回的json做点自己想做的事情了,亲自试过了头条,抖音,巨量引擎,京东等网站。
以上就是抖音喜欢列表怎么翻到最早的的全部内容,希望能够对大家有所帮助。
相关阅读
- 抖音喜欢列表怎么倒序(抖音喜欢列表怎么倒序查看)
- 破解抖音喜欢列表的软件(怎样破解抖音的喜欢列表)
- 抖音喜欢列表会自动清理吗(抖音的喜欢列表会自动删除吗)
- 隐藏抖音喜欢列表(抖音喜欢列表可以隐藏)
- 抖音清理喜欢列表(抖音喜欢列表清理成功)
- 抖音不能看对方的喜欢列表了(抖音不能看到对方的喜欢)
- 抖音怎样把喜欢隐藏(抖音怎样把喜欢隐藏我喜欢列表没有)
- 电脑版抖音怎么打开喜欢列表
- 抖音怎么开放我的喜欢电脑网页版(抖音怎么开放我的喜欢电脑网页版呢)
- 抖音如何查看别人的喜欢列表(如何查看抖音号等级)
- 抖音增加管理员(抖音增加管理员怎么弄)
- 抖音手机直播背景如何换成自己的(抖音手机直播手游)
- 怎么把下载的电影片段发到抖音(怎么把下载的电影片段发到抖音上)
- 苹果平板mini4可以下载抖音吗(苹果mini4平板多少钱)
- 抖音热播电影虎牙(抖音热播电影虎牙怎么看)
- 抖音不帮手机号可以发作品吗
热门文章
猜您喜欢









最新手机软件
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10










